
-min")
Summary
written for:
Introduction
Model Development
- Building a Model
- Evaluate the Model
- Deploy the Model
Speed Metric
Improving Accuracy
One such method that meets Bag of Freebies’ definition is Data Augmentation, commonly used in object detection to improve Accuracy. Data Augmentation focuses on boosting input image variability so that the constructed object detection model is more resilient to images acquired from various environments.

Improving Speed
- Model Pruning
- Model Precision Change
- Hardware specific optimization
Model Pruning is the process of deleting unused nodes to reduce the number of learnable parameters. Pruning requires the model to be retrained with an entire dataset to adjust the learnable parameters for the change we introduced.
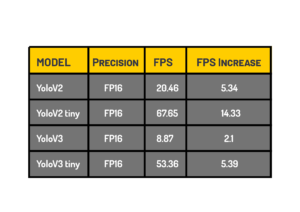
Model Precision can also be reduced to improve speed. Usually, the CNN models are trained at higher precision, say FP32, you can reduce the model to FP16 or INT8 precision to improve the speed. The vital thing to remember here is that you need to check if your target hardware can handle these precision levels. Also, changing the model to INT8 precision requires a process called Quantization, a calibration done with the minimal or full dataset used for training.
Additionally, some of the SoC vendors provide tools for optimizing the model with respect to their hardware, and we can utilize them to optimize our model performance. For example, for Jetson boards, Nvidia provides TensorRT, which takes the model as input and is optimized for the target hardware to run faster with minimal Accuracy loss during the deployment stage on the Edge device.