
People/ Human detection and tracking were critical monitoring system features due to their relevance for prompt identification of persons, human activity recognition, and scene analysis. According to the real-time use-case, we can accelerate the human/people detection model by 20% by working and training a dataset. This podcast covers the different perspectives of human/people detection technical metrics.
4 questions this podcast will answer:
01
How and when bounding box and segmentation approach is utilised in people detection?02
What are The six significant technical terms required to understand people detection accuracy metrics?03
When to use average precision (AP) and Mean average precision (mAP)?04
List three demonstration scenarios for implementing and discussing accuracy metricsRelevant links:


Podcast Transcript:
Hi, this is Alphonse, and in this episode of unravelling computer vision and Edge AI for the real world, I’ll talk about what specific metrics you should use to assess the accuracy of your people detection solution based on particular use cases.
So first, before we get into the metrics, let’s look into how people are detected.
We basically use two different ways to identify people. The first is the bounding box detection approach. In this approach, people get detected with bounding box values at the output.
A bounding box is nothing but a rectangle over the images, which outlines the object within each image by defining its x and y coordinates and width and hit height within the image.
The second approach is the segmentation approach. Here we group together the pixels that have similar attributes and create a pixel voice mask for each object in the image. So, this gives us a far more granular understanding of the object in the image. Well, within segmentation, there are two types in semantic segmentation.
We just say if the pixel belongs to the person in the background whilst, in instance, we go to a granular level and say which pixel belongs to which person.
So basically, while semantic segmentation helps detect the person, instant segmentation helps you classify the person or recognise the person, so now you understand how to detect people, let’s get just get down to the accuracy metrics.
For bounding box detection approach, the commonly used detection metrics are average precision and mean average precision, but then before getting into these metrics, we need to understand some of the technical terms which we use to define these metrics so that we can better understand how to measure the accuracy of object detection.
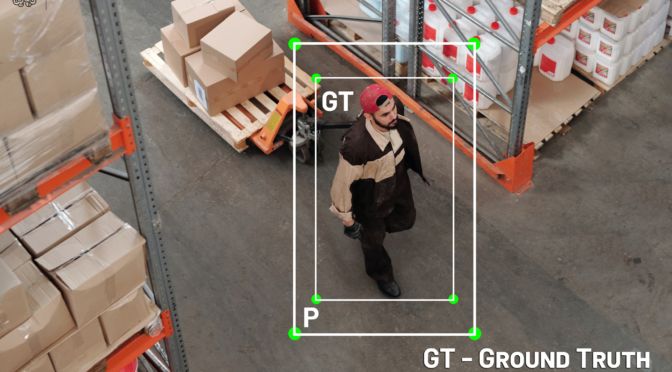
The first technical term is ground truth. Ground truth is nothing but the hand label bounding boxes that show where the image the actual objects are. Also, while precision is the ability of a model to identify only the relevant objects.
A recall is the ability of a model to find all the relevant cases. For example, consider an image that is having five people a model that finds only one of these five people but correctly labels it as a person has perfect precision but imperfect recall.
In addition to these technical terms, we also need to understand what is a confusion matrix
in a confusion matrix, we need to understand the true positive means that a person who’s detected is actually a person, while false positive means the person who’s detected is not a person true and false negatives should also be looked upon in a similar way.
And finally, one of the most important terms you should understand is intersection over union, which is a measure that evaluates the overlap between ground truth and rotating bounding boxes and predicted bounding boxes the lower the IoU, the lower is your prediction result.
So now that we understand these technical terms. One of the most popular metrics we use in measuring the accuracy of object detection solutions like SSD, Yolo, etc., is average precision.
In average precision, we use the average precision value for recall value over 0 to 1. The general definition for average precision is that you need to find the area under the precision-recall curve.
This precision-recall curve shows you the trade-off between precision and recall for different thresholds. A high area under this curve represents both high recall and high precision, whilst high precision means that you have a low false-positive rate. Your high recall actually means you have a low false-negative rate, but all this holds good only when you focus on a single class of objects.
But in object detection, we can have more than one class right, so this is where mean average precision comes into play. It is the mean of ap across all the classes, and it is used to identify the accuracy of a people reduction solution. Let us take these metrics and see how it looks in different use cases.
In the first scenario, let’s see what would be the mean average precision value when ground truth and prediction are the same.
Here the mean average precision will have the maximum value of 1 because precision-recall will remain at 1 as there is no false positive or a false negative, which makes the mean average precision to be 1, right?
Now let us look at the second scenario. Let’s see what the mean average precision would be if there is no match with the ground truth.
Um, here, the mean average precision should be zero because the true positive is zero, which means that the precision and recall is also zero. Therefore, mean average precision or the accuracy of your model is actually 0.
Now let us look into another scenario on what the mean average precision value would be if there are more false positives in the prediction, in addition to the fact that it predicted all the ground truth.
So here, the false positives will reduce the precision, and the mean average precision will reduce because there’s an increase in false positives, so we can say that the high false positives will reduce the mean average precision even though the true positive is high.
Finally, looking into all these accuracy metrics, it’s also important to remember that we need to devise proper testing strategies for each and every one of them, and this is a very con time-consuming task that takes you away from the all-important task of building a solution which can add stakeholder value and most importantly solve the problem.
Also, an algorithm is just one part of the overall solution. Choosing the right hardware, such as an Edge processor or an embedded camera, along with building a scalable analytics engine on the cloud to make sense of your data flowing in from your edge devices, is a complicated problem.
Here at VisAI labs, we have a people detection pro platform, which has a pre-tested combination of ready to deploy Edge hardware and Edge optimised algorithms for major use cases such as conjunction reduction, dwell time detection, intrusion reduction, and also the social distancing checker for both indoor and outdoor environments.
We can help you solve your algo problems so that you can solve your real-world problems with Edge AI and computer vision.
Thank you for tuning in to yet another episode of unravelling computer vision and Edge AI for the real world. This is Alphonse signing off!
